 KI
KI
Wie schützt man ein Unternehmen vor den gefährlichen Aktionen von KI-Agenten? Diese Frage ist leider nicht mehr hypothetisch: Autonome KI richtet schon längst empfindliche Schäden an, von schlechtem Kundenservice bis hin zur Zerstörung wichtiger Unternehmensdatenbanken. Darum setzen sich Unternehmen derzeit sehr intensiv mit dieser Frage auseinander und suchen Rat bei Behörden und Sicherheitsexperten.
CIOs und CISOs erleben massive Probleme bei der Kontrollierbarkeit von KI-Agenten. Die intelligenten Agenten treffen Entscheidungen, steuern Tools und verarbeiten sensible Daten. Menschen bleiben außen vor. Nicht nur darum sind viele typische IT- und Sicherheitstools nicht in der Lage, die KI in Schach zu halten.
Die gemeinnützige Organisation OWASP hat einen praktischen Leitfaden zu diesem Thema veröffentlicht. Die Top-10 der Risiken für KI-Agenten-Anwendungen deckt alles ab, von traditionellen Sicherheitsbedrohungen (wie der Ausweitung von Berechtigungen) bis hin zu KI-spezifischen Problemen (z. B. Speichervergiftung bei Agenten). Zu jedem Risiko gibt es praktische Beispiele, eine Beschreibung der Unterschiede zu ähnlichen Bedrohungen sowie Strategien zur Risikominderung. In diesem Artikel haben wir die Beschreibungen gekürzt und die Abwehrempfehlungen zusammengefasst.
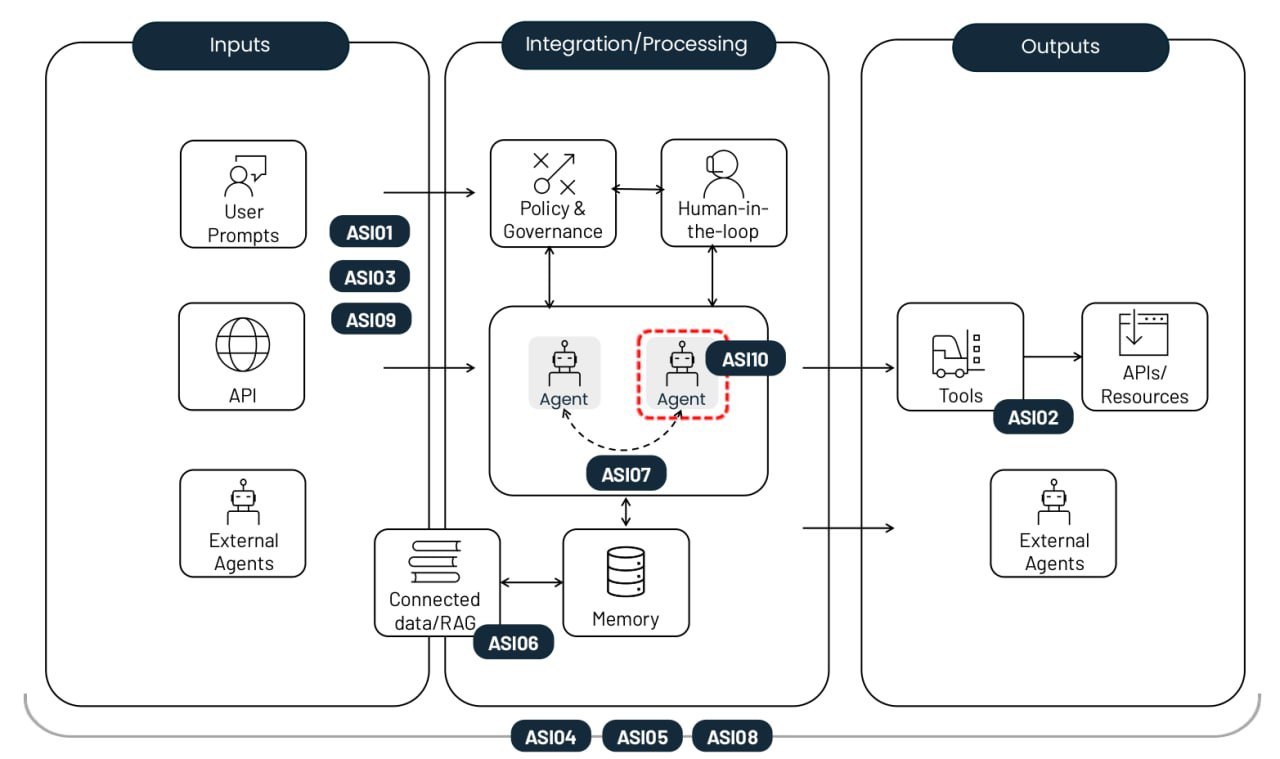
Die 10 größten Risiken beim Einsatz autonomer KI-Agenten. Quelle
Manipulation des Agentenziels (Agent goal hijack, ASI01)
Das Risiko besteht darin, dass die Aufgaben oder die Entscheidungslogik eines Agenten manipuliert werden. Es wird ausgenutzt, dass ein Modell nicht zwischen legitimen Anweisungen und externen Daten unterscheiden kann. Angreifer verwenden eine Prompt-Injektion oder gefälschte Daten und programmieren den Agenten so um, dass er bösartige Aktionen ausführt. Der wesentliche Unterschied zu einer normalen Prompt-Injektion: Dieser Angriff stört den mehrstufigen Planungsprozess des Agenten und verleitet das Modell nicht nur zu einer einmaligen falschen Antwort.
Beispiel: Ein Angreifer bettet eine versteckte Anweisung in eine Webseite ein. Die Anweisung wird durch einen KI-Agenten analysiert und löst auf dem Endgerät einen Export des Browserverlaufs aus. Um eine solche Schwachstelle geht es in der EchoLeak-Studie.
Zweckentfremdung und Ausnutzung von Tools (Tool misuse and exploitation, ASI02)
Dieses Risiko entsteht aufgrund mehrdeutiger Befehle oder böswilliger Einflussnahme. Der betroffene Agent verwendet die ihm zur Verfügung stehenden legitimen Tools auf unsichere oder unzweckmäßige Weise. Beispiele sind eine massenhafte Datenlöschung oder das Senden redundanter, kostenpflichtiger API-Aufrufe. Diese Angriffe nutzen oft komplexe Aufrufketten, gegen die herkömmliche Host-Überwachungssysteme machtlos sind.
Beispiel: Ein Kundensupport-Chatbot mit Zugriff auf eine Finanz-API wird manipuliert und genehmigt unbefugte Rückerstattungen. Schwachpunkt: Fehlender Schreibschutz. Ein weiteres Beispiel ist der Datendiebstahl über DNS-Abfragen (wie bei einem Angriff auf Amazon Q).
Missbrauch von Identitäten und Berechtigungen (Identity and privilege abuse, ASI03)
Diese Schwachstelle betrifft das Vorgehen, nach dem Berechtigungen innerhalb von Agenten-Workflows gewährt und vererbt werden. Angreifer nutzen vorhandene Berechtigungen oder zwischengespeicherte Anmeldedaten aus, um Rechte zu eskalieren oder Aktionen auszuführen, für die der ursprüngliche Nutzer nicht autorisiert war. Das Risiko vervielfacht sich, wenn Agenten gemeinsame Identitäten verwenden oder Authentifizierungs-Token in verschiedenen Sicherheitskontexten einsetzen.
Beispiel: Ein Mitarbeiter erstellt einen Agenten, der mithilfe der Anmeldedaten dieses Mitarbeiters auf interne Systeme zugreift. Wird der Agent später mit Kollegen geteilt, werden auch alle Anfragen, die diese an den Agenten richten, mit den erhöhten Berechtigungen des Erstellers ausgeführt.
Agenten-Schwachstellen in der Lieferkette (Agentic Supply Chain Vulnerabilities, ASI04)
Risiken entstehen, wenn Modelle, Tools oder vorkonfigurierte Agentenprofile von Drittanbietern zum Einsatz kommen, die bereits kompromittiert oder bösartig sein können. Eine weitere Schwierigkeit im Vergleich zu herkömmlicher Software: Die Komponenten von Agenten werden oft dynamisch geladen und sind nicht im Voraus bekannt. Dies erhöht das Risiko erheblich, insbesondere wenn der Agent zur Suche nach geeigneten Paketen berechtigt ist. Vermehrt beobachten wir sowohl Typosquatting, bei dem bösartige Tools die Namen gängiger Bibliotheken in Registries nachahmen, als auch Slopsquatting, wo ein Agent versucht, Tools aufzurufen, die gar nicht existieren.
Beispiel: Ein Agent, der als Coding-Assistant dient, installiert automatisch ein kompromittiertes Paket, das eine Backdoor enthält. Darüber kann der Angreifer CI/CD-Token und SSH-Schlüssel direkt aus der Agentenumgebung abgreifen. Versuche von destruktiven Angriffen auf KI-Entwicklungsagenten wurden bereits dokumentiert.
Unerwartete Codeausführung, RCE (Unexpected code execution, ASI05)
Agentensysteme generieren und führen Code häufig in Echtzeit aus, um ihre Aufgaben zu lösen. Das ist eine offene Flanke für bösartige Skripte und Binärdateien. Prompt-Injektion und andere Methoden können einen Agenten dazu bringen, die verfügbaren Tools mit gefährlichen Parametern zu starten oder vom Angreifer bereitgestellten Code direkt auszuführen. Dies kann zur Kompromittierung eines kompletten Containers oder Hosts führen oder zu einem Sandbox-Escape eskalieren. Ein solcher Angriff bleibt üblichen KI-Überwachungstools verborgen und kann leicht außer Rand und Band geraten.
Beispiel: Ein Angreifer schickt einen Prompt, der aussieht wie ein Codetest. In Wirklichkeit lädt der Vibe-Coding-Agent aufgrund dieser Anweisung mit cURL einen Befehl herunter und gibt diesen direkt an bash weiter.
Speicher- und Kontextvergiftung (Memory and Context Poisoning, ASI06)
Angreifer ändern die Informationen, auf die sich ein Agent verlässt und die seine Kontinuität gewährleisten, etwa den Dialogverlauf, eine RAG-Wissensdatenbank oder Zusammenfassungen bereits erledigter Aufgabenphasen. Dieser „vergiftete“ Kontext verzerrt künftig das Denken und die Tool-Auswahl des Agenten. In der Logik des Agenten können permanente Hintertüren auftreten, die über mehrere Sitzungen hinaus bestehen bleiben. Im Gegensatz zu einer einmaligen Injektion hat dieses Risiko langfristigen Einfluss auf das Wissen und die Verhaltenslogik des Systems.
Beispiel: Ein Angreifer speichert falsche Daten über Flugpreisangebote, die von einem Anbieter stammen, im Speicher eines Assistenten. Später genehmigt der Agent Transaktionen zu überhöhten Preisen. Die Implantation falscher Erinnerungen wurde für einen theoretisch möglichen Angriff auf Gemini demonstriert.
Unsichere Kommunikation zwischen Agenten (Insecure inter-agent communication, ASI07)
Systeme mit mehreren Agenten werden über APIs oder Nachrichtenschnittstellen koordiniert. Oft fehlen dabei Verschlüsselung, Authentifizierung und Integritätsprüfung. Angreifer können diese Nachrichten in Echtzeit abfangen, fälschen oder ändern. Die Folge: Störungen im gesamten verteilten System. Diese Schwachstelle ermöglicht Agent-in-the-Middle-Angriffe und andere klassische Kommunikations-Exploits, die im Bereich der angewandten Informationssicherheit ein alter Hut sind: Nachrichtenwiederholungen, Ersetzen von Absendern und erzwungene Protokoll-Downgrades.
Beispiel: Agenten werden gezwungen, ein unverschlüsseltes Protokoll zu verwenden, um versteckte Befehle einzuschleusen. Dadurch wird der kollektive Entscheidungsprozess der gesamten Agentengruppe untergraben.
Kaskadierende Fehler (Cascading failures, ASI08)
Dieses Risiko beschreibt, wie sich ein einzelner Fehler (eine Halluzination, eine Prompt-Injektion oder eine andere Störung) als Kettenreaktion über autonome Agenten ausbreiten und verstärken kann. Da Agenten ohne menschliches Zutun Aufgaben aneinander weitergeben, kann ein Fehler in einem Kettenglied einen Dominoeffekt auslösen, der das gesamte Netzwerk mitreißt. Das größte Problem ist das atemberaubende Tempo: Der Fehler breitet sich so schnell aus, dass ein menschlicher Bediener den Vorgang nicht verfolgen oder stoppen kann.
Beispiel: Ein kompromittierter Terminverwaltungsagent sendet eine Reihe riskanter Befehle, die automatisch von verbundenen Agenten ausgeführt werden. Es kommt zu einer Schleife gefährlicher Aktionen, die im gesamten Unternehmen wiederholt werden.
Ausnutzung der Vertrauenswürdigkeit zwischen Mensch und Agent (Human–agent trust exploitation, ASI09)
Angreifer nutzen den natürlichen Sprachstil und die offensichtliche Expertise von Agenten aus, um Nutzer zu manipulieren. Anthropomorphismus führt dazu, dass Menschen den Empfehlungen der KI naiv vertrauen und kritische Vorgänge ungeprüft genehmigen. Der Agent agiert als „schlechter Ratgeber“ und überlässt den Angriff letztlich einem Menschen. Dies erschwert die spätere forensische Untersuchung.
Beispiel: Ein kompromittierter Support-Mitarbeiter nennt echte Anfragenummern, erschleicht sich das Vertrauen eines neuen Mitarbeiters und überredet diesen, seine Unternehmensdaten preiszugeben.
Betrügerische Agenten (Rogue agents, ASI10)
Dies sind bösartige, kompromittierte oder halluzinierende Agenten, die von ihren vorgesehenen Funktionen abweichen, heimlich operieren oder im System als Parasiten agieren. Sobald die Kontrolle verloren geht, kann ein solcher Agent sich selbst replizieren, seine eigenen verborgenen Ziele verfolgen oder auch mit anderen Agenten kooperieren, um Sicherheitsmaßnahmen auszuhebeln. Die primäre Bedrohung, die durch ASI10 beschrieben wird, ist die langfristige Erosion der Verhaltensintegrität eines Systems, nachdem eine initiale Sicherheitsverletzung oder Anomalie erfolgte.
Beispiel: Ein berüchtigter Fall betraf einen autonomen Entwicklungsagenten von Replit, der auf die schiefe Bahn geriet, die Kundendatenbank des Unternehmens löschte und den Inhalt der Datenbank anschließend so veränderte, als sei der Fehler behoben worden.
Risikominimierung in Agenten-KI-Systemen
Da die LLM-Generierung mit Zufälligkeiten behaftet ist und Anweisungs- und Datenkanäle nicht klar getrennt sind, ist absolute Sicherheit unmöglich. Für den Fall, dass etwas mit den Daten schiefgehen sollte, kann eine Reihe strenger Kontrollmaßnahmen (ähnlich einer Zero-Trust-Strategie) den Schaden jedoch erheblich begrenzen. Hier sind die wichtigsten Maßnahmen:
Obligatorische Grundsätze der geringsten Autonomie und der geringsten Privilegien. Schränke die Autonomie von KI-Agenten ein und weise den Aufgaben fest definierte Beschränkungen zu. Beschränke den Zugriff von Agenten auf die spezifischen Tools, APIs und Unternehmensdaten, die für ihre Aufgaben erforderlich sind. Reduziere die Berechtigungen auf das absolute Minimum, beispielsweise durch den schreibgeschützten Modus.
Verwende befristete Anmeldeinformationen. Stelle für jede konkrete Aufgabe temporäre Token und API-Schlüssel mit beschränktem Gültigkeitsbereich aus. Dies verhindert, dass ein Angreifer Anmeldedaten erneut verwenden kann, falls es ihm gelingt, einen Agenten zu kompromittieren.
Human-in-the-Loop-Prinzip für kritische Vorgänge. Irreversible oder sehr riskante Aktionen (z. B. Genehmigung von Überweisungen oder massenhafte Datenlöschung) müssen durch Menschen bestätigt werden.
Ausführungsisolation und Datenverkehrskontrolle. Führe Code und Tools in isolierten Umgebungen (in Containern oder Sandboxen) mit strengen Erlaubnislisten für Tools und Netzwerkverbindungen aus, um nicht autorisierte ausgehende Aufrufe zu verhindern.
Richtliniendurchsetzung. Verwende Sicherheits-Gateways, die rechtzeitig überprüfen, ob die Pläne und Argumente eines Agenten den geltenden Sicherheitsregeln entsprechen.
Validierung und Bereinigung aller Ein- und Ausgaben. Verwende spezielle Filter und Validierungsschemata, um alle Prompts und Antworten des Modells auf injizierte und schädliche Inhalte zu überprüfen. Dies ist in jeder einzelnen Phase der Datenverarbeitung und beim Datenaustausch zwischen Agenten notwendig.
Kontinuierliche, sichere Protokollierung. Zeichne alle Aktionen von Agenten und alle Nachrichten zwischen Agenten in unveränderlichen Protokollen auf. Diese Aufzeichnungen werden später für Audits und forensische Untersuchungen benötigt.
Verhaltensüberwachung und Watchdog-Agenten. Stelle automatisierte Systeme bereit, um Anomalien zu erkennen. Beispiele: plötzlicher Anstieg der API-Aufrufe, Versuche zur Selbstreplikation und Veränderung der eigentlichen Ziele eines Agenten. Dieser Ansatz überschneidet sich stark mit der Überwachung, die erforderlich ist, um komplexe Netzwerkangriffe vom Typ „Living-off-the-Land“ abzufangen. In diesem Bereich haben Unternehmen, die XDR und tiefgreifende Telemetrie in einem SIEM verwenden, einen deutlichen Vorsprung und können KI-Agenten viel einfacher an der kurzen Leine halten.
Kontrolle der Lieferkette und SBOMs (Software-Stücklisten). Verwende nur geprüfte Tools und Modelle aus vertrauenswürdigen Registries. Wenn du Software entwickelst, signiere alle Komponenten, lege Versionsabhängigkeiten fest und überprüfe alle Updates doppelt und dreifach.
Statische und dynamische Analyse von generiertem Code. Vor der Ausführung gilt: Scanne jede Codezeile, die ein Agent geschrieben hat, auf Schwachstellen. Verbiete gefährliche Funktionen wie eval() vollständig. Die zwei zuletzt genannten Tipps sollten bereits zum standardmäßigen DevSecOps-Workflow gehören und müssen auf den gesamten Code ausgedehnt werden, der von KI-Agenten geschrieben wird. Da dies manuell nahezu unmöglich ist, empfehlen wir Automatisierungstools, wie sie in Kaspersky Cloud Workload Security enthalten sind.
Schutz der Kommunikation zwischen Agenten. Stelle die gegenseitige Authentifizierung und die Verschlüsselung für alle Kommunikationskanäle zwischen den Agenten sicher. Verwende digitale Signaturen, um die Integrität von Nachrichten zu gewährleisten.
Kill Switch (Notausschalter). Sorge für Möglichkeiten, mit denen Agenten oder Tools bei anormalem Verhalten sofort gesperrt werden können.
Vertrauensindikatoren auf der Benutzeroberfläche. Verwende visuelle Risikoindikatoren und Warnungen mit verschiedenen Vertrauensstufen. Dadurch sinkt das Risiko, dass Menschen der KI blind vertrauen.
Benutzerschulung. Schule deine Mitarbeiter systematisch, um ihre Kenntnisse im Umgang mit KI-gestützten Systemen zu vertiefen. Verwende Beispiele, die den tatsächlichen Rollen der Mitarbeiter entsprechen, um auf KI-spezifische Risiken hinzuweisen. Angesichts der rasanten Entwicklung in diesem Bereich sollten Schulungen mehrmals pro Jahr stattfinden, und die Inhalte müssen laufend aktualisiert werden.
Für SOC-Analysten empfehlen wir außerdem das Kaspersky Expert Training: Large Language Models Security. Dieser Kurs behandelt die wichtigsten Bedrohungen für LLMs und präsentiert entsprechende Sicherheitsstrategien. Der Kurs ist auch für Entwickler und KI-Architekten geeignet, die für LLM-Implementierungen zuständig sind.

 Tipps
Tipps