 Threat Intelligence
Threat Intelligence
Cybersicherheitsexperten streiten sich darüber: Lohnt es sich wirklich, bei Angriffen auf Unternehmen genau herauszufinden, wer die Fäden hinter der Malware in der Hand hält. Die Untersuchung von Vorfällen verläuft gewöhnlich wie folgt ab: Der Analyst findet eine verdächtige Datei → Wenn das Antivirenprogramm die Datei nicht blockiert hat, kommt sie zum Testen in eine Sandbox → Dort wird eine bösartige Aktivität bestätigt → Der Hash wird zur Sperrliste hinzugefügt → Der Analyst macht eine Kaffeepause. Nach diesem Schema gehen viele Cybersicherheitsexperten vor – insbesondere, wenn sie von Warnungen überhäuft werden oder ihre forensischen Fähigkeiten nicht ausreichen, um einen komplexen Angriff bis ins letzte Detail aufzuklären. Bei einem gezielten Angriff kann dieses Vorgehen jedoch in einer Katastrophe enden. Und zwar aus folgendem Grund:
Wenn es ein Angreifer ernst meint, bleibt es selten bei einem einzigen Angriffsvektor. Es ist nicht unwahrscheinlich, dass die bösartige Datei, die du gefunden hast, bereits an einem mehrstufigen Angriff beteiligt war und für den Angreifer inzwischen so gut wie nutzlos ist. Möglicherweise ist der Bösewicht bereits tief in die Infrastruktur des Unternehmens eingedrungen und bedient sich ganz anderer Werkzeuge. Um die Bedrohung wirklich zu beseitigen, muss das Sicherheitsteam die Angriffskette sorgfältig analysieren und auf allen Ebenen neutralisieren.
Doch wie geht dies schnell und effektiv, bevor die Angreifer echten Schaden anrichten? Eine Möglichkeit besteht darin, den Kontext ganz genau zu untersuchen. Durch die Analyse einer Datei kann ein Experte den Angreifer genau identifizieren, die eingesetzten Tools und Taktiken herausfinden und die Infrastruktur anschließend auf entsprechende Bedrohungen durchsuchen. Es gibt viele Tools zur Bedrohungsanalyse. Ein gutes Beispiel ist unser Kaspersky Threat Intelligence Portal.
Ein praktisches Beispiel für die Bedeutung der Attribution
Angenommen, wir haben eine Malware-Datei gefunden, laden sie auf ein Threat Intelligence-Portal hoch und stellen fest, dass sie häufig von der Gruppe MysterySnail eingesetzt wird. Was kann uns das sagen? Diese Informationen sind verfügbar:
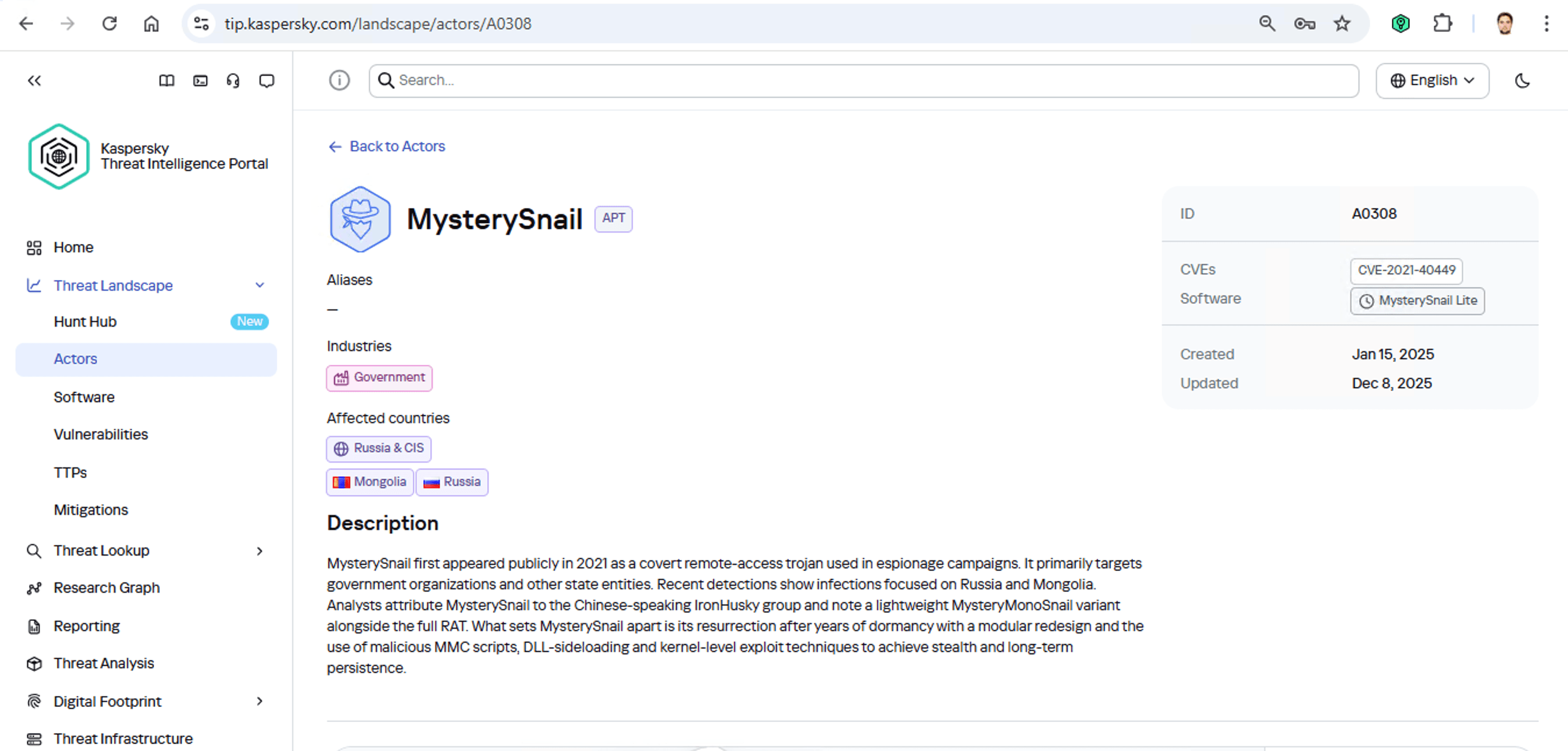
Diese Angreifer haben es auf staatliche Einrichtungen in Russland und in der Mongolei abgesehen. Es ist eine chinesischsprachige Gruppe, die auf Spionage spezialisiert ist. Laut Beschreibung nisten sich die Angreifer in der Infrastruktur ein und verhalten sich unauffällig, bis sie etwas Interessantes entdecken. Außerdem nutzen sie normalerweise die Schwachstelle CVE-2021-40449 aus. Was ist das für eine Schwachstelle?
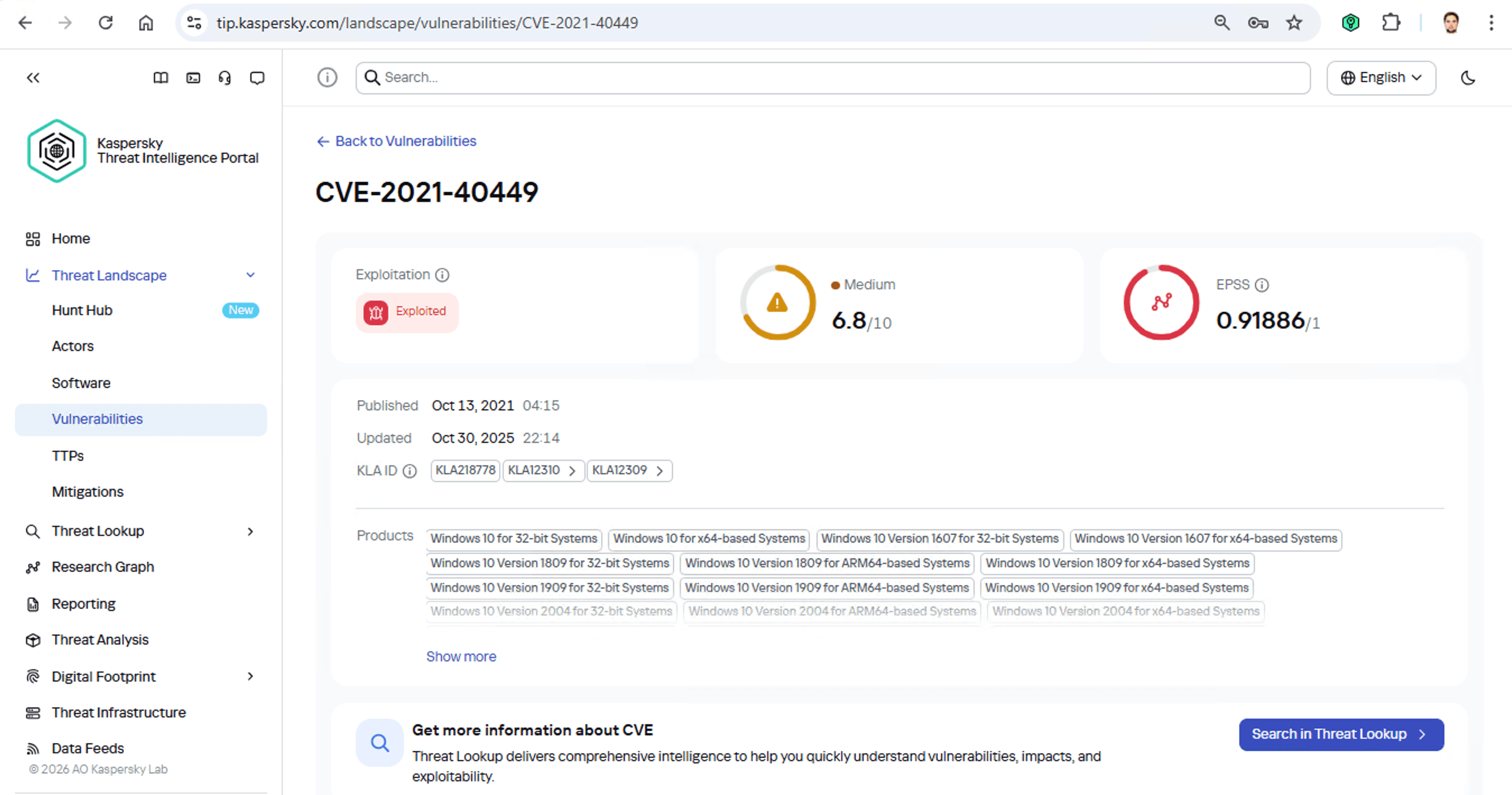
Sie dient zur Ausweitung von Berechtigungen und wird eingesetzt, nachdem Hacker bereits in die Infrastruktur eingedrungen sind. Diese Schwachstelle ist sehr riskant und wird sehr häufig ausgenutzt. Welche Software ist von dieser Schwachstelle betroffen?
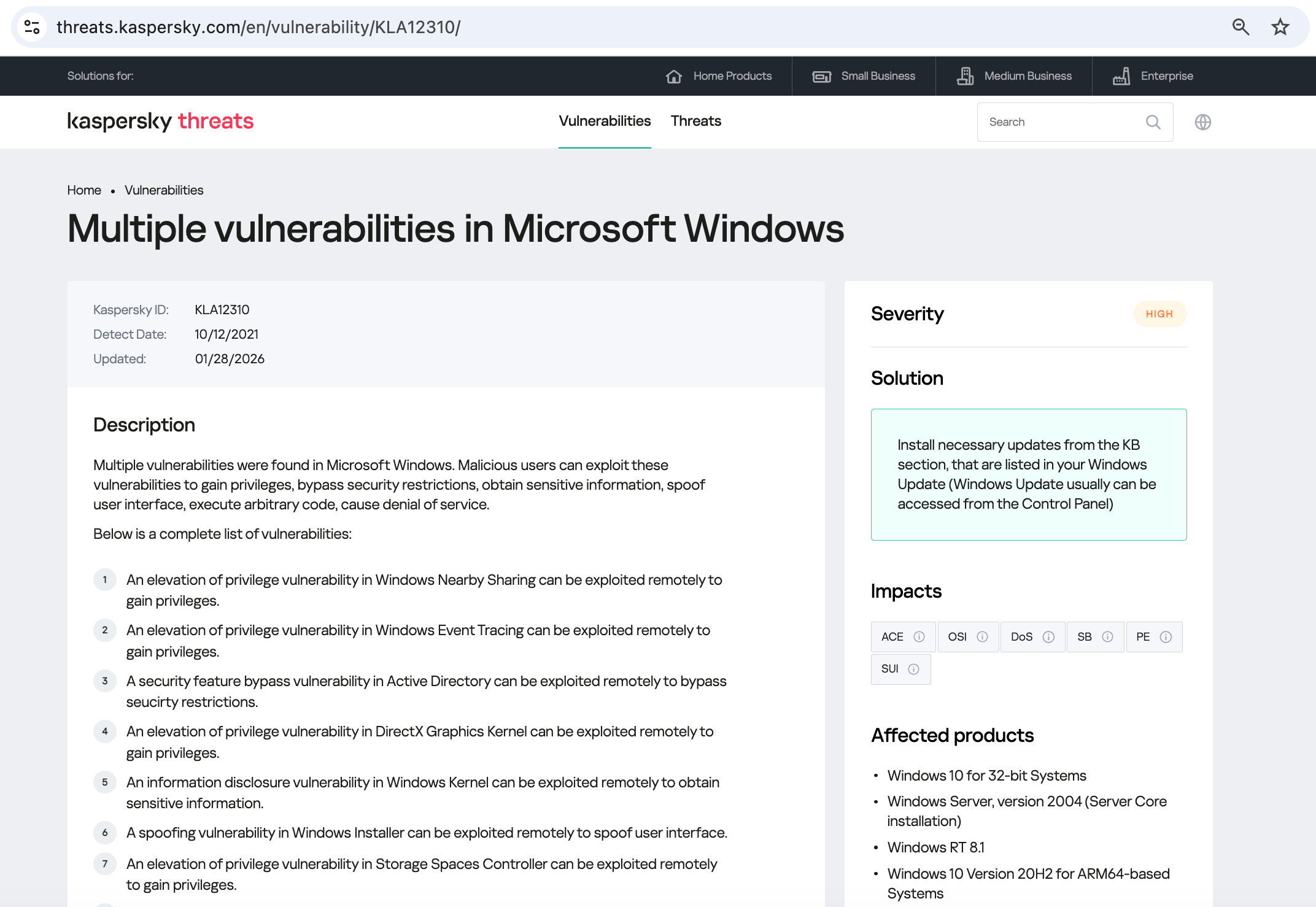
Ganz klar: Microsoft Windows. Zwischenergebnis: Es muss überprüft werden, ob der Patch, der diese Lücke schließt, installiert ist. Was wissen wir außer dieser Schwachstelle noch über die Hacker? Wie sich herausstellt, haben sie eine spezielle Methode, um die Netzwerkkonfiguration zu studieren: Sie verbinden sich mit der öffentlichen Website 2ip.ru:

Es ist also sinnvoll, eine Korrelationsregel zum SIEM hinzuzufügen, damit solches Verhalten erkannt wird.
Dann informieren wir uns genauer über diese Gruppe und erstellen zusätzliche Kompromittierungsindikatoren (IoCs) für die SIEM-Überwachung sowie gebrauchsfertige YARA-Regeln (strukturierte Textbeschreibungen zur Malware-Identifizierung). Dadurch können wir alle Fangarme des Ungetüms aufspüren, die bereits in die Unternehmensinfrastruktur hineinreichen. Und künftige Angriffe können zuverlässig abgewehrt werden.
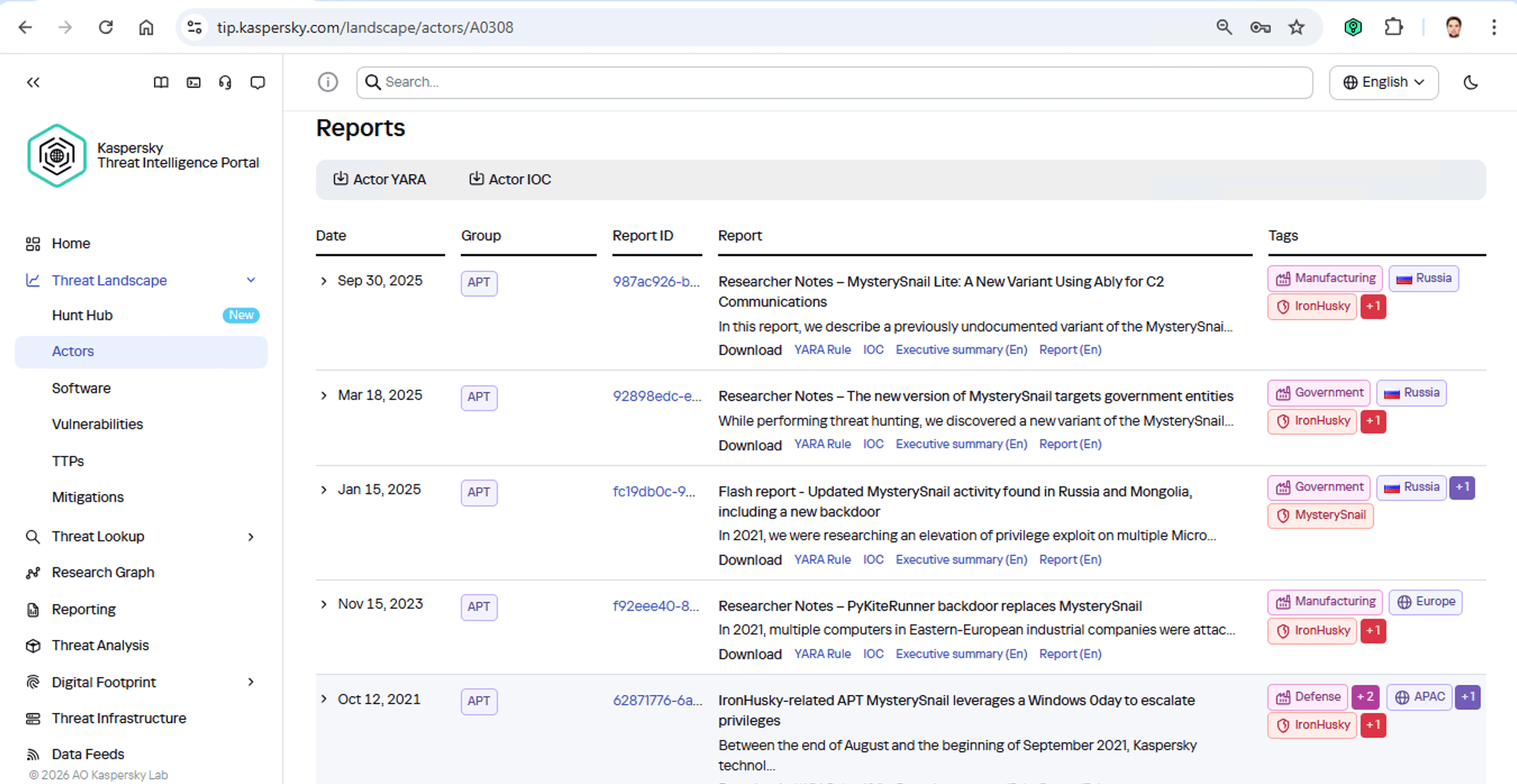
Kaspersky Threat Intelligence Portal stellt eine Vielzahl zusätzlicher Berichte über MysterySnail-Bedrohungen bereit, und für jeden Bericht gibt es eine Liste mit IoCs und YARA-Regeln. Anhand dieser YARA-Regeln können alle Endpunkte gescannt werden. Die IoCs können zum SIEM hinzugefügt werden, um eine permanente Überwachung zu gewährleisten. Aus den Berichten können wir auch entnehmen, wie diese Angreifer Daten exfiltrieren und nach welchen Datenarten sie normalerweise suchen. Daraus ergeben sich praktische Schritte zur Abwehr des Angriffs.
Pech gehabt, MysterySnail! Die Infrastruktur ist jetzt darauf eingerichtet, dich zu finden und sofort zu reagieren. Schluss mit Spionieren!
Methoden zur Malware-Attribution
Bevor wir über konkrete Methoden sprechen, wollen wir klarstellen: Damit die Attribution tatsächlich funktioniert, benötigt die eingesetzte Threat Intelligence eine umfangreiche Wissensbasis zu den Taktiken, Techniken und Prozeduren (TTPs), die von Angreifern genutzt werden. Umfang und Qualität dieser Datenbanken können von Anbieter zu Anbieter stark variieren. Vor der Entwicklung unseres Tools haben wir beispielsweise jahrelang die Kampagnen bekannter Gruppen verfolgt und die entsprechenden TTPs protokolliert. Diese Datenbank wird natürlich laufend aktualisiert.
Mit einer gut bestückten TTP-Datenbank können die folgenden Attributionsmethoden implementiert werden:
- Dynamische Attribution: TTPs werden durch dynamische Analyse bestimmter Dateien identifiziert. Anschließend wird diese Auswahl mit den TTPs bekannter Hackergruppen abgeglichen.
- Technische Attribution: In bestimmten Dateien und Codefragmenten, die von bekannten Hackergruppen in ihrer Malware genutzt werden, wird nach Übereinstimmungen gesucht.
Dynamische Attribution
Die Identifizierung von TTPs durch eine dynamische Analyse lässt sich relativ einfach implementieren und ist schon lange Standard in allen modernen Sandboxen. Natürlich nutzen auch alle unsere Sandboxen die dynamische Analyse und identifizieren dabei die TTPs eines Malware-Musters:
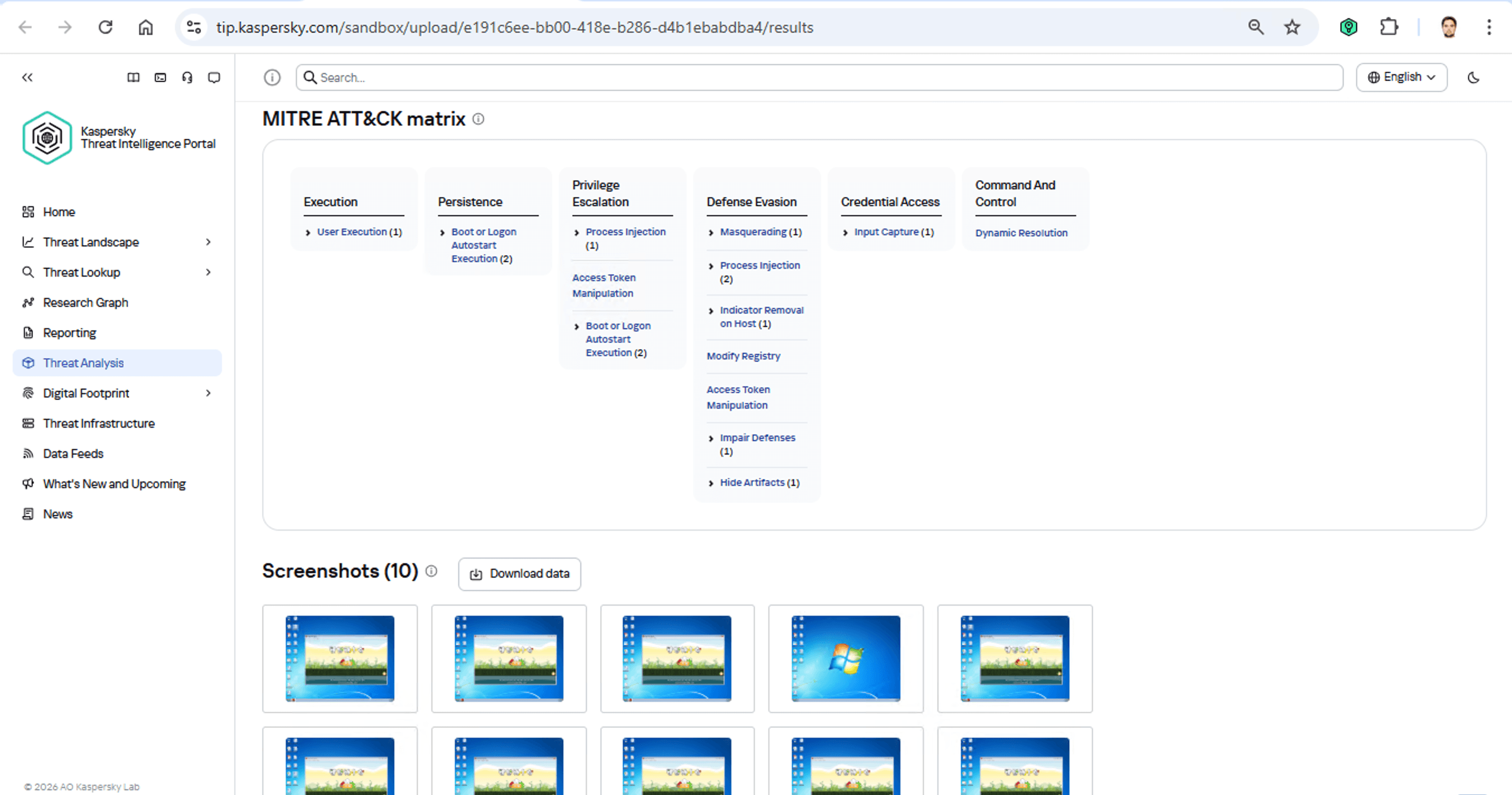
Der Kern dieser Methode ist die Kategorisierung von Malware-Aktivität anhand des MITRE ATT&CK-Frameworks. Ein Sandbox-Bericht enthält normalerweise eine Liste der erkannten TTPs. Diese Daten sind zwar sehr nützlich, reichen jedoch nicht aus, um den Angriff zuverlässig einer bestimmten Gruppe zuzuordnen. Der Versuch, auf diese Weise die Initiatoren eines Angriffs zu finden, ähnelt dem altindischen Gleichnis von den Blinden und dem Elefanten: Menschen mit verbundenen Augen berühren verschiedene Körperteile eines Elefanten und versuchen herauszufinden, womit sie es zu tun haben. Wer den Rüssel anfasst, hält den Elefanten für eine Python. Wer ihn an der Seite berührt, ist sich sicher, es handelt sich um eine Wand, und so weiter.

Technische Attribution
Die zweite Attributionsmethode beruht auf statischer Codeanalyse (die Attribution immer gewissen Probleme birgt). Der Grundidee besteht darin, selbst Malware-Dateien mit nur geringfügiger Überlappung aufgrund bestimmter einzigartiger Merkmale in Gruppen zusammenzufassen. Vor Beginn der Analyse muss das Malware-Muster zerlegt werden. Problem: Der wiederhergestellte Code enthält neben den informativen und brauchbaren Teilen auch viel Rauschen. Wenn der Attributionsalgorithmus auch diesen nicht informativen „Müll“ berücksichtigt, sieht jedes Malware-Muster am Ende wie eine große Anzahl legitimer Dateien aus. Dann ist eine brauchbare Zuordnung unmöglich. Andererseits führt der Versuch, den Code nur anhand nützlicher Fragmente, aber auf mathematisch primitive Weise zuzuordnen, ebenfalls zu einer übermäßig hohen Anzahl von falsch positiven Zuordnungsergebnissen. Darüber hinaus muss jedes Attributionsergebnis auf Ähnlichkeiten mit legitimen Dateien überprüft werden. Dabei hängt die Qualität dieser Überprüfung stark von den technischen Möglichkeiten des Herstellers ab.
Attribution bei Kaspersky
Unsere Produkte nutzen eine einzigartige Datenbank für Malware, die bestimmten Hackergruppen zugeordnet ist. Diese Datenbank wurde über mehr als 25 Jahre hinweg aufgebaut. Darüber hinaus verwenden wir einen patentierten Attributionsalgorithmus, der auf der statischen Analyse von zerlegtem Code basiert. Dadurch können wir mit hoher Genauigkeit und sogar mit einem Wahrscheinlichkeitswert (in Prozent) bestimmen, welche Ähnlichkeit eine analysierte Datei mit bekannten Mustern aus einer bestimmten Gruppe hat. Auf diese Weise können wir uns ein fundiertes Urteil bilden und die Malware einem konkreten Angreifer zuordnen. Die Ergebnisse werden dann mit einer Datenbank aus Milliarden legitimer Dateien abgeglichen, um falsch positive Ergebnisse herauszufiltern. Wenn eine Übereinstimmung gefunden wird, wird das Attributionsverdikt entsprechend angepasst. Dieser Ansatz ist das Rückgrat der Kaspersky Threat Attribution Engine und darauf basiert auch der Attributionsdienst von Kaspersky Threat Intelligence Portal.
